Llama 3.2 on serverless infrastructure like AWS Lambda
This guide will demonstrate using Llama 3.2 1B on serverless infrastructure. Llama 3.2 1B is a lightweight model, which makes it interesting for serverless applications since it can be run relatively quickly without requiring GPU acceleration. We'll use models from Hugging Face and Nitric to manage the surrounding infrastructure, such as API routes and deployments.
Prerequisites
- uv - for Python dependency management
- The Nitric CLI
- (optional) An AWS account
Project setup
Let's start by creating a new project using Nitric's python starter template.
nitric new llama py-startercd llama
Next, let's install the base dependencies, then add the extra dependencies we need specifically for loading the language model.
# Install the base dependenciesuv sync# Add the llama-cpp-python dependencyuv add llama-cpp-python
Choose a Llama model
Llama 3.2 is available in different sizes and configurations, each with its own trade-offs in terms of performance, accuracy, and resource requirements. For serverless applications without GPU acceleration (such as AWS Lambda), it's important to choose a model that is lightweight and efficient to ensure it runs within the constraints of that environment.
We'll use a quantized version of the lightweight Llama 1B model, specifically Llama-3.2-1B-Instruct-Q4_K_M.gguf.
If you're not familiar with Quantization it's a technique that reduces a model's size and resource requirements, which in our case makes it suitable for serverless applications, but may impact the accuracy of the model.
The LM Studio team provides several quantized versions of Llama 3.2 1B on Hugging Face. Consider trying different versions to find one that best fits your needs (e.g. Q5_K_M which is slightly larger but higher quality).
Let's download the chosen model and save it in a models directory in your project.
Download link for Llama-3.2-1B-Instruct-Q4_K_M.gguf
mkdir modelscd models# This model is 0.81GB, it may take a little while to downloadcurl -OL https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF/resolve/main/Llama-3.2-1B-Instruct-Q4_K_M.ggufcd ..
Your folder structure should look like this:
/llama/modelsLlama-3.2-1B-Instruct-Q4_K_M.gguf/servicesapi.pynitric.yamlpyproject.tomlpython.dockerfilepython.dockerfile.ignoreREADME.mduv.lock
Create a service to run the model
Next, we'll use Nitric to create an HTTP API that allows you to send prompts to the Llama model and receive the output in a response. The API will return the raw output from the model, but you can adjust this as you see fit.
Replace the contents of services/api.py with the following code, which loads the Llama model and implements the prompt functionality. Take a little time to understand the code. It defines an API with a single endpoint /prompt that accepts a POST request with a prompt in the body. The process_prompt function sends the prompt to the Llama model and returns the response.
from nitric.resources import apifrom nitric.application import Nitricfrom nitric.context import HttpContextfrom llama_cpp import Llama# Load the locally stored Llama modelllm = Llama(model_path="./models/Llama-3.2-1B-Instruct-Q4_K_M.gguf")# Function to execute a prompt using the Llama modeldef process_prompt(user_prompt):system_prompt = "You are a helpful assistant."# See https://www.llama.com/docs/model-cards-and-prompt-formats/llama3_1/ for details about prompt formatprompt = (# System Promptf'<|start_header_id|>system<|end_header_id|>{system_prompt}<|eot_id|>'# User Promptf'<|start_header_id|>user<|end_header_id|>{user_prompt}<|eot_id|>'# Start assistants turn (we leave this open ended as the assistant hasn't started its turn)f'<|start_header_id|>assistant<|end_header_id|>')response = llm(prompt=prompt,# Unlimited, consider setting a token limitmax_tokens=-1,temperature=0.7,)return response# Define an API for the prompt servicemain = api("main")@main.post("/prompt")async def handle_prompt(ctx: HttpContext):# assume the input is text/plainprompt = ctx.req.datatry:ctx.res.body = process_prompt(prompt)except Exception as e:print(f"Error processing prompt: {e}")ctx.res.body = {"error": str(e)}ctx.res.status = 500Nitric.run()
Ok, let's run this thing!
Now that you have an API defined, we can test it locally. The python starter template uses python3.11-bookworm-slim as its basic container image, which doesn't have the right dependencies to load the llama model, let's update the dockerfile to use python3.11-bookworm (the non-slim version) instead.
# The python version must match the version in .python-version-FROM ghcr.io/astral-sh/uv:python3.11-bookworm-slim AS builder+FROM ghcr.io/astral-sh/uv:python3.11-bookworm AS builder-FROM python:3.11-slim-bookworm+FROM python:3.11-bookworm
Now we can run our services locally:
nitric run
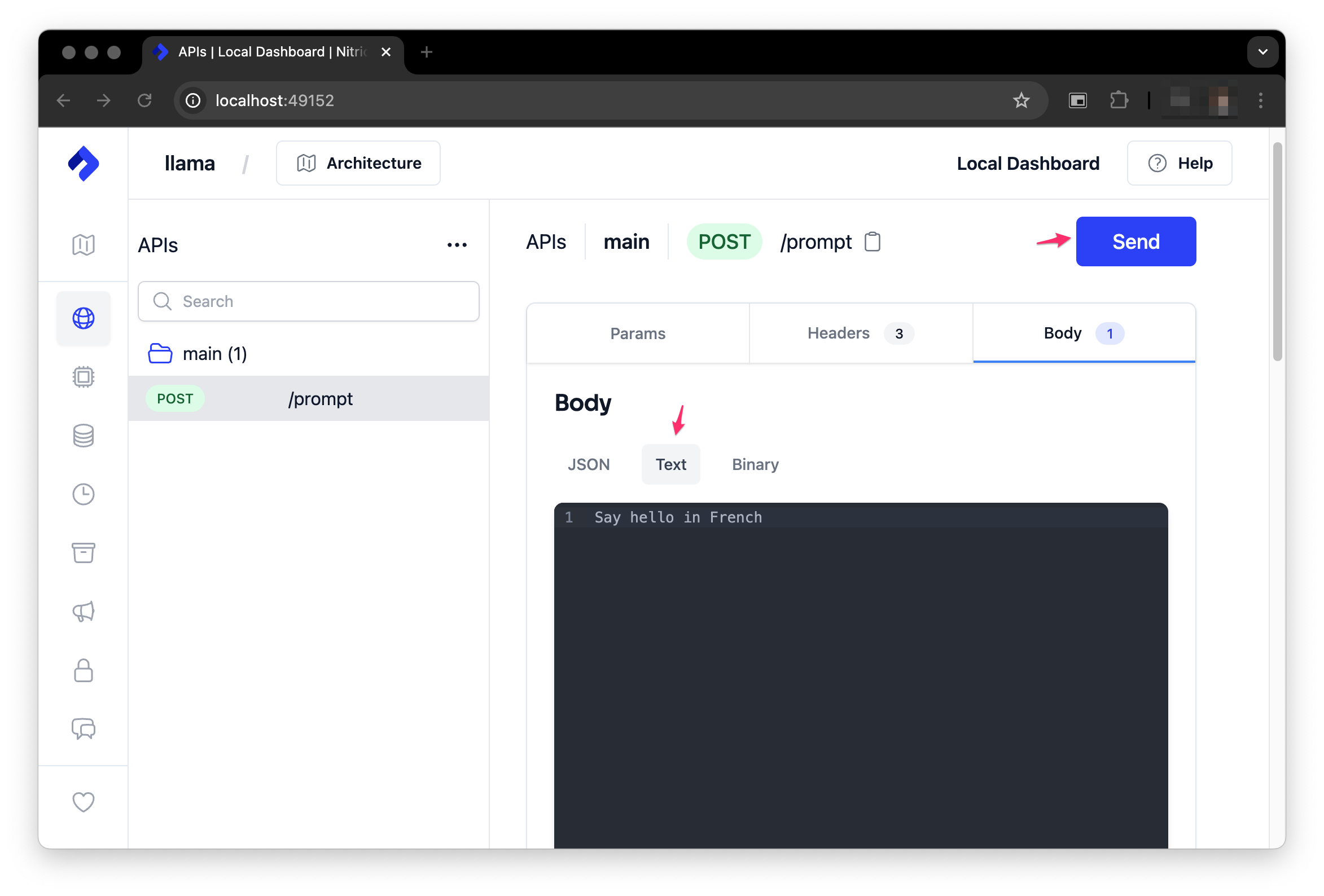
Once it starts, you can test it with the Nitric Dashboard.
You can find the URL to the dashboard in the terminal running the Nitric CLI, by default it's http://localhost:49152. Add a prompt to the body of the request and send it to the /prompt endpoint.
Deploying to AWS
When you're ready to deploy the project, we can create a new Nitric stack file which will target AWS:
nitric stack new dev aws
Update the stack file nitric.dev.yaml with the appropriate AWS region and memory allocation to handle the model.
provider: nitric/aws@1.16.0region: us-east-1config:# How services will be deployed by default, if you have other services not running models# you can add them here too so they don't use the same configurationdefault:lambda:# Set the memory to 6GB to handle the model, this automatically sets additional CPU allocationmemory: 6144# Set a timeout of 30 seconds (this is the most API Gateway will wait for a response)timeout: 30# We add more storage to the lambda function, so it can store the modelephemeral-storage: 1024
Nitric defaults aim to keep you within your free-tier limits. In this example, we recommend increasing memory and ephemeral values to allow the llama model to load correctly, therefore running this sample project will likely incur more costs than a Nitric guide using the defaults. You are responsible for staying within the limits of the free tier or any costs associated with deployment.
Since we'll use Nitric's default Pulumi AWS Provider make sure you're setup to deploy using that provider. You can find more information on how to set up the AWS provider in the Nitric AWS Provider documentation.
If you'd like to deploy with Terraform or to another cloud provider, that's also possible. You can find more information about how Nitric can deploy to other platforms in the Nitric Providers documentation.
You can then deploy using the following command:
nitric up
Take note of the API endpoint URL that is output after the deployment is complete.
If you're done with the project later, tear it down with nitric down
Testing on AWS
To test the service, you can use any API testing tool you like, such as cURL, Postman, etc. Here's an example using cURL:
curl -X POST {your endpoint URL here}/prompt -d "Hello, how are you?"
Example response
The response will include the results, plus other metadata. The output can be found in the choices array.
{"id": "cmpl-61064b38-45f9-496d-86d6-fdae4bc3db97","object": "text_completion","created": 1729655327,"model": "./models/Llama-3.2-1B-Instruct-Q4_K_M.gguf","choices": [{"text": "\"I'm doing well, thank you for asking. I'm here and ready to assist you, so that's a good start! How can I help you today?\"","index": 0,"logprobs": null,"finish_reason": "stop"}],"usage": {"prompt_tokens": 26,"completion_tokens": 33,"total_tokens": 59}}
Summary
At this point, we demonstrated how you can use a lightweight model like Llama 3.2 1B with serverless compute, enabling the application to quickly respond to prompts without the need for GPU acceleration, on relatively low-cost infrastructure.
As you've seen in the code example, we've setup a fairly basic prompt structure, but you can expand on this to include more complex prompts. Including system prompts that help restrict/guide the model's responses, or even more complex interactions with the model. Also, in this example we expose the model directly as an API, but this limits the response time to 30 seconds on AWS with API Gateway.
In future guides we'll show how you can go beyond simple one-time responses to more complex interactions, such as maintaining context between requests. We can also include Websockets and streamed responses to provide a better user experience for larger responses.
Have feedback on this page?
Open GitHub Issue