Transcribing Podcasts using OpenAI Whisper
Prerequisites
- uv - for Python dependency management
- The Nitric CLI
- (optional) An AWS account
Getting started
We'll start by creating a new project using Nitric's python starter template.
If you want to take a look at the finished code, it can be found here.
nitric new podcast-transcription py-startercd podcast-transcription
Next, let's install our base dependencies, then add the openai-whisper library as an optional dependency.
We are adding numba==0.60 as librosa is currently forcing an outdated
version. This may be removed in the future pending this
issue
# Install the base dependenciesuv sync# Add OpenAI whisper dependencyuv add openai-whisper librosa numpy numba==0.60 --optional ml
We add the extra dependencies to the 'ml' optional dependencies to keep them separate since they can be quite large. This lets us just install them in the containers that need them.
We'll organize our project structure like so:
+--common/| +-- __init__.py| +-- resources.py+--batches/| +-- transcribe.py+--services/| +-- api.py+--.gitignore+--.python-version+-- pyproject.toml+-- python.dockerfile+-- python.dockerignore+-- nitric.yaml+-- transcribe.dockerfile+-- transcribe.dockerignore+-- README.md
Define our resources
We'll start by creating a file to define our Nitric resources. For this project we'll need an API, Batch Job, and two buckets, one for the audio files to be transcribed and one for the resulting transcripts. The API will interface with the buckets, while the Batch Job will handle the transcription.
from nitric.resources import job, bucket, apimain_api = api("main")transcribe_job = job("transcribe")podcast_bucket = bucket("podcasts")transcript_bucket = bucket("transcripts")
Add our transcription services
Now that we have defined resources, we can import our API and add some routes to access the buckets as well as a storage listener that is triggered by new podcasts added to a bucket.
from common.resources import main_api, transcript_bucket, podcast_bucket, transcribe_jobfrom nitric.application import Nitricfrom nitric.resources import BucketNotificationContextfrom nitric.context import HttpContextreadable_transcript_bucket = transcript_bucket.allow("read")writable_podcast_bucket = podcast_bucket.allow("write")submittable_transcribe_job = transcribe_job.allow("submit")# Get a podcast transcript from the bucket# Get a URL for uploading podcasts to the buckets# Trigger a bucket notification on any write notifications to the podcast bucketNitric.run()
Downloading our model
We can download our model and embed it into our container to reduce the start up time of our transcription. We'll create a script which can be triggered using uv run download_model.py --model_name turbo.
from whisper import _MODELS, _downloadimport argparseimport osdefault = os.path.join(os.path.expanduser("~"), ".cache")download_root = os.path.join(os.getenv("XDG_CACHE_HOME", default), "whisper")def download_whisper_model(model_name="base"):print("downloading model...")# if we have the original download go to the default whisper cachemodel = _download(_MODELS[model_name], root=download_root, in_memory=True)# make sure the ./model directory existsos.makedirs("./.model", exist_ok=True)# write the model to disksave_path = f"./.model/model.pt"with open(save_path, "wb") as f:f.write(model)print(f"Model '{model_name}' has been downloaded and saved to './model/model.pt'.")if __name__ == "__main__":parser = argparse.ArgumentParser(description="Download a Whisper model.")parser.add_argument("--model_name", type=str, default="base", help="Name of the model to download.")args = parser.parse_args()download_whisper_model(model_name=args.model_name)
Add Transcribe Batch Job
For the job, we'll be setting the memory to 12000. If you're using anything less than the large model this should be safe. You can see the memory requirements for each of the model sizes below.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
We can create our job using the following code:
import whisperimport ioimport numpy as npimport osimport librosafrom common.resources import transcribe_job, transcript_bucket, podcast_bucketfrom nitric.context import JobContextfrom nitric.application import Nitric# Set permissions for the transcript bucket for writingwriteable_transcript_bucket = transcript_bucket.allow("write")# Set permissions for the podcast bucket for readingreadable_podcast_bucket = podcast_bucket.allow("read")# Get the location of the modelMODEL = os.environ.get("MODEL", "./.model/model.pt")@transcribe_job(cpus=1, memory=12000, gpus=0)async def transcribe_podcast(ctx: JobContext):podcast_name = ctx.req.data["podcast_name"]print(f"Transcribing: {podcast_name}")# Read the bytes from the podcast that was uploaded to the bucketpodcast = await readable_podcast_bucket.file(podcast_name).read()# Convert the audio bytes into a numpy array for the models consumptionpodcast_io = io.BytesIO(podcast)y, sr = librosa.load(podcast_io)audio_array = np.array(y)# Load the local whisper modelmodel = whisper.load_model(MODEL)# Transcribe the model and make the output verbose# We can turn off `FP16` with `fp16=False` which will use `FP32` instead.# This will depend on what is supported on your CPU when testing locally, however, `FP16` and `FP32` are supported on Lambda.result = model.transcribe(audio_array, verbose=True, fp16=False)# Take the outputted transcript and write that to the transcript buckettranscript = result["text"].encode()print("Finished transcoding... Writing to Bucket")await writeable_transcript_bucket.file(f"{podcast_name}-transcript.txt").write(transcript)print("Done!")return ctxNitric.run()
Deployment Dockerfiles
With our code complete, we can write a dockerfile that our batch job will run in. It's split into 3 main sections, with 2 stages.
- The base image that copies our application code and resolves the dependencies using
uv. - The next stage is to build upon our base with another image with Nvidia drivers. It sets environment variables to enable GPU use and download Python 3.11 with apt.
- Get our application from the base image and run our application.
ln -sf /usr/bin/python3.11 /usr/local/bin/python3 && \ln -sf /usr/bin/python3.11 /usr/local/bin/python
We'll add a dockerignore to help reduce the size of the Docker Image that is being deployed.
.mypy_cache/.nitric/.venv/nitric-spec.jsonnitric.yamlREADME.md
And add ./model to the python docker ignore.
.mypy_cache/.nitric/.venv/.model/nitric-spec.jsonnitric.yamlREADME.md
Finally, we can update the project file to point our batch job to our new dockerfile. We also want to add the batch-services to our enabled preview features.
name: podcast-transcriptionservices:- match: services/*.pystart: uv run watchmedo auto-restart -p *.py --no-restart-on-command-exit -R uv run $SERVICE_PATHruntime: pythonbatch-services:- match: batches/*.pystart: uv run watchmedo auto-restart -p *.py --no-restart-on-command-exit -R uv run $SERVICE_PATHruntime: transcriberuntimes:python:dockerfile: python.dockerfiletranscribe:dockerfile: transcribe.dockerfilepreview:- batch-services
Testing the project
Before deploying our project, we can test that it works as expected locally. You can do this using nitric start or if you'd prefer to run the program in containers use nitric run. Either way you can test the transcription by first uploading an audio file to the podcast bucket.
You can find most free podcasts for download by searching for it on Podbay.
You can upload the podcast directly to the bucket using the local dashboard or use the API to do it instead. If you want to use the API, start by getting the upload URL for the bucket.
curl http://localhost:4002/podcast/serialhttp://localhost:55736/write/eyJhbGciOi...
We'll then use the URL to put our data binary. I've stored the podcast as serial.mp3.
curl -X PUT --data-binary @"serial.mp3" http://localhost:55736/write/eyJhbGciOi...
Once that's done, the batch job will be triggered so you can just sit back and watch the transcription logs. When it finishes you can download the transcription from the bucket using the following cURL request.
curl -sL http://localhost:4002/transcript/serial
Requesting a G instance quota increase
Most AWS accounts will not have access to on-demand GPU instances (G Instances), if you'd like to run models using a GPU you'll need to request a quota increase for G instances.
If you prefer not to use a GPU you can set gpus=0 in the @transcribe_podcast decorator in batches/transcribe.py. The model runs pretty well on CPU, so a GPU is not entirely necessary.
Important: If the gpus value in batches/transcribe.py exceeds the number
of available GPUs in your AWS account, the job will never start. If you want
to run without a GPU, make sure to set gpus=0 in the @transcribe_podcast
decorator. This is just a quirk of how AWS Batch works.
If you want to use a GPU you'll need to request a quota increase for G instances in AWS.
To request a quota increase for G instances in AWS you can follow these steps:
- Go to the AWS Service Quotas for EC2 page.
- Find/Search for Running On-Demand G and VT instances
- Click Request quota increase
- Choose an appropriate value, e.g. 4, 8 or 16 depending on your needs
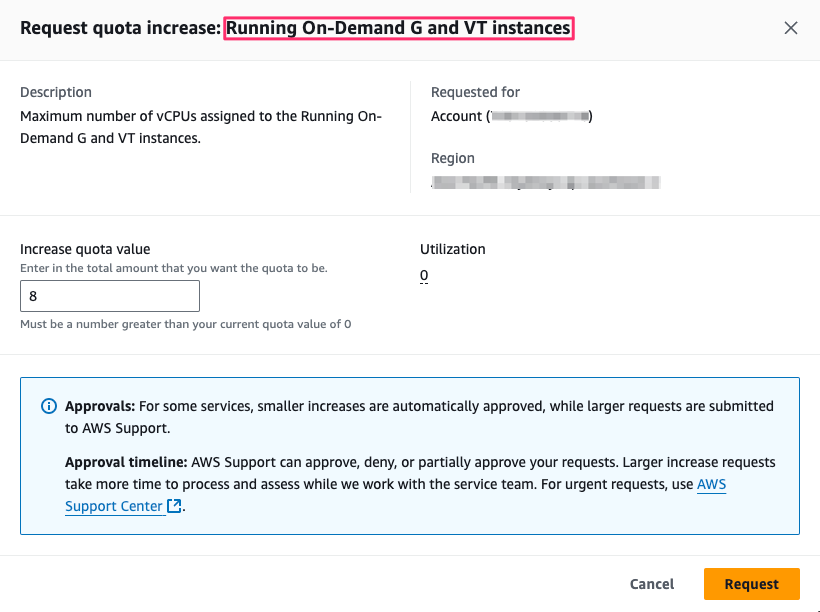
Once you've requested the quota increase it may take time for AWS to approve it.
Deploy the project
At this point, you can deploy what you've built to any of the supported cloud providers. In this example we'll deploy to AWS. Start by setting up your credentials and configuration for the nitric/aws provider.
Next, we'll need to create a stack file (deployment target). A stack is a deployed instance of an application. You might want separate stacks for each environment, such as stacks for dev, test, and prod. For now, let's start by creating a file for the dev stack.
The stack new command below will create a stack named dev that uses the aws provider.
nitric stack new dev aws
Edit the stack file nitric.dev.yaml and set your preferred AWS region, for example us-east-1.
provider: nitric/aws@latestregion: us-east-1
You are responsible for staying within the limits of the free tier or any costs associated with deployment.
Let's try deploying the stack with the up command:
nitric up
The initial deployment may take time due to the size of the python/Nvidia driver and CUDA runtime dependencies.
Once the project is deployed you can try out some transcriptions, just add a podcast to the bucket and the bucket notification will be triggered.
To tear down your application from the cloud, use the down command:
nitric down
Summary
In this guide, we've created a podcast transcription service using OpenAI Whisper and Nitric's Python SDK. We showed how to use batch jobs to run long-running workloads and connect these jobs to buckets to store generated transcripts. We also demonstrated how to expose buckets using simple CRUD routes on a cloud API. Finally, we were able to create dockerfiles with GPU support to optimize the generation speeds on the cloud.
For more information and advanced usage, refer to the Nitric documentation.
Have feedback on this page?
Open GitHub Issue