

How much time should teams be spending on infrastructure? If your developers and operations teams are busy writing, troubleshooting and maintaining infrastructure code, they're losing time for delivering features for the business. How can you make sure your teams are employing the most effective ways to deploy to the cloud?
Cloud Deployment with Infrastructure as Code vs. Infrastructure from Code
Infrastructure as Code (IaC) brought infrastructure deployment out of the dark ages by providing frameworks that allow for the predictable and testable deployment of complex cloud infrastructure through declarative and versionable definitions. This allowed infrastructure deployments to be much more reliable and repeatable.
In the DevOps and cloud automation space we're seeing the emergence of a new paradigm in the way we build and architect applications for the cloud known as "Infrastructure from Code" or "Self-provisioning runtimes" that builds upon IaC.
Infrastructure from Code (IfC) builds on the ideas and technologies of IaC. It provides all of the same benefits around predictable and testable infrastructure deployment but aims to abstract away explicit infrastructure declaration, instead opting for a more implicit approach using the intent expressed by the code of the application to be deployed.
Convenience vs. Control in Cloud Deployment
Software engineers have been making trade-offs between convenience and control for decades.
Abstraction is a key way that convenience has been introduced in a variety of development scenarios. With increasing layers of abstraction, we introduce new opinions about the way things should be done so consumers of this abstraction no longer have to worry about those concepts.
A prime example of this in the software world is higher-order languages; by surrendering control of lower-level concepts, we can become more productive and focused on the functional goals of the software that is being implemented.
The implicit abstraction of IfC does come at a cost; while developers no longer need to concern themselves with the minutia of infrastructure deployment, there is friction if a need arises to be more explicit about infrastructure requirements. This trade-off between convenience and control is captured in the below diagram, with examples of where some existing technologies fit on this spectrum.
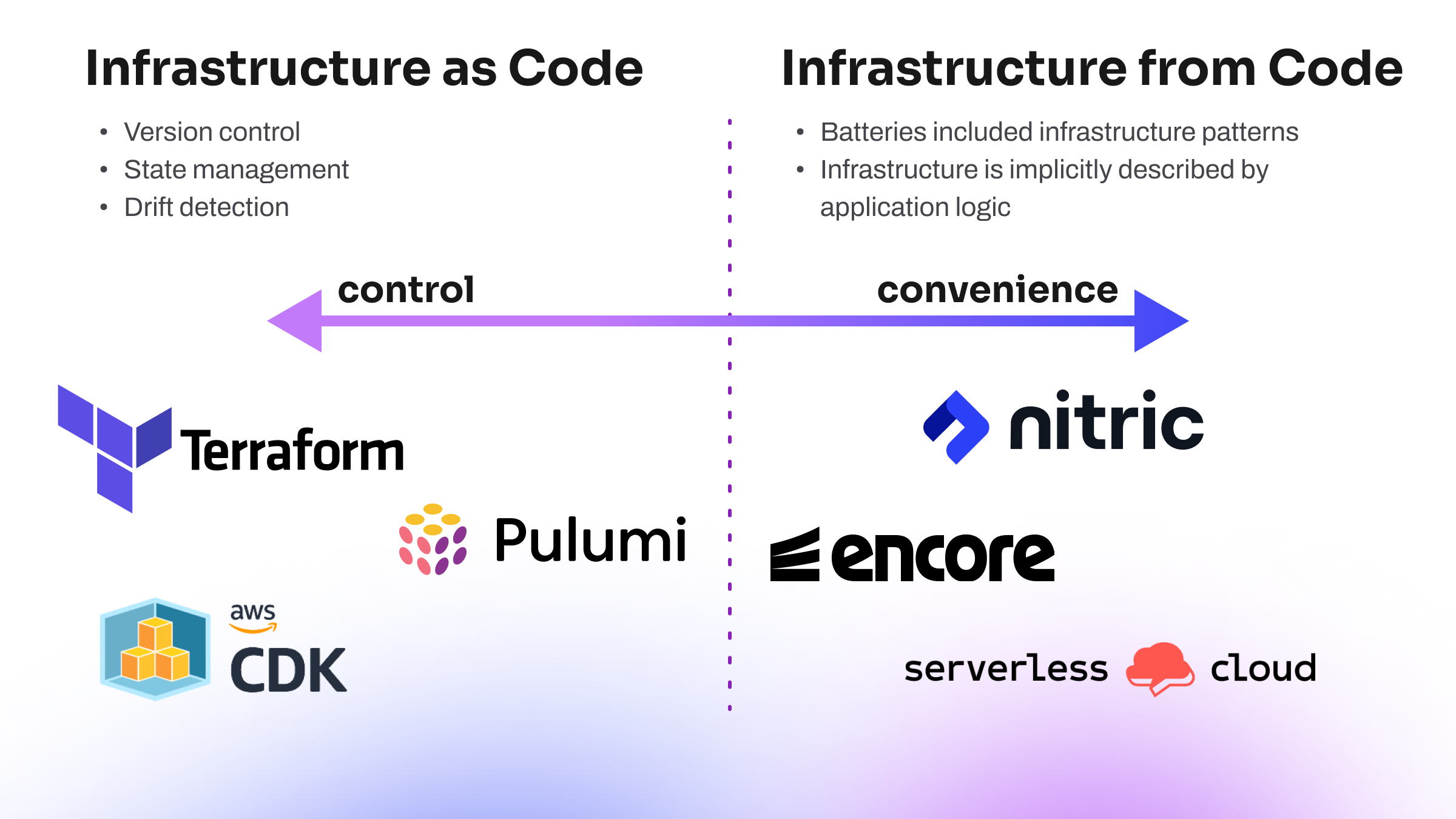
It's important to note that IfC does not need to be considered a replacement for IaC tools. Instead, IfC introduces a method of bringing developer self-service for infrastructure directly into the developer application. Teams can enhance IaC by using IfC alongside tools like Pulumi or Terraform.
IaC vs. IfC in Practice
Cloud deployment is a notoriously complex undertaking and one where many application development teams are looking for more convenience. Let’s take a look at how IaC and IfC technologies provide varying convenience vs. control. We'll demonstrate the benefits of convenience over control, by deploying a “Hello World” application to AWS using frameworks along the spectrum. First see what IaC looks like for Terraform vs. Pulumi, then see the same example implemented with IfC through Nitric.
Deploying to AWS with Terraform
For those not familiar, Terraform is an IaC framework maintained by Hashicorp. It uses a syntax known as HCL (Hashicorp Configuration Language) to express infrastructure requirements in a declarative and versionable syntax for creating consistent infrastructure deployments. It has a very large community and is currently a leader in the IaC space.
Here’s the Terraform script for our “Hello World” example:
terraform {required_providers {aws = {source = "hashicorp/aws"version = "~> 4.0.0"}random = {source = "hashicorp/random"version = "~> 3.1.0"}archive = {source = "hashicorp/archive"version = "~> 2.2.0"}}required_version = "~> 1.0"}provider "aws" {region = var.aws_region}resource "random_pet" "lambda_bucket_name" {prefix = "learn-tf"length = 4}resource "aws_s3_bucket" "lambda_bucket" {bucket = random_pet.lambda_bucket_name.idforce_destroy = true}resource "aws_s3_bucket_acl" "lambda_bucket_acl" {bucket = aws_s3_bucket.lambda_bucket.idacl = "private"}data "archive_file" "lambda_hello_world" {type = "zip"source_dir = "${path.module}/hello-world"output_path = "${path.module}/hello-world.zip"}resource "aws_s3_object" "lambda_hello_world" {bucket = aws_s3_bucket.lambda_bucket.idkey = "hello-world.zip"source = data.archive_file.lambda_hello_world.output_pathetag = filemd5(data.archive_file.lambda_hello_world.output_path)}resource "aws_lambda_function" "hello_world" {function_name = "HelloWorld"s3_bucket = aws_s3_bucket.lambda_bucket.ids3_key = aws_s3_object.lambda_hello_world.keyruntime = "nodejs12.x"handler = "hello.handler"source_code_hash = data.archive_file.lambda_hello_world.output_base64sha256role = aws_iam_role.lambda_exec.arn}resource "aws_cloudwatch_log_group" "hello_world" {name = "/aws/lambda/${aws_lambda_function.hello_world.function_name}"retention_in_days = 30}resource "aws_iam_role" "lambda_exec" {name = "serverless_lambda"assume_role_policy = jsonencode({Version = "2012-10-17"Statement = [{Action = "sts:AssumeRole"Effect = "Allow"Sid = ""Principal = {Service = "lambda.amazonaws.com"}}]})}resource "aws_iam_role_policy_attachment" "lambda_policy" {role = aws_iam_role.lambda_exec.namepolicy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"}resource "aws_apigatewayv2_api" "lambda" {name = "serverless_lambda_gw"protocol_type = "HTTP"}resource "aws_apigatewayv2_stage" "lambda" {api_id = aws_apigatewayv2_api.lambda.idname = "serverless_lambda_stage"auto_deploy = trueaccess_log_settings {destination_arn = aws_cloudwatch_log_group.api_gw.arnformat = jsonencode({requestId = "$context.requestId"sourceIp = "$context.identity.sourceIp"requestTime = "$context.requestTime"protocol = "$context.protocol"httpMethod = "$context.httpMethod"resourcePath = "$context.resourcePath"routeKey = "$context.routeKey"status = "$context.status"responseLength = "$context.responseLength"integrationErrorMessage = "$context.integrationErrorMessage"})}}resource "aws_apigatewayv2_integration" "hello_world" {api_id = aws_apigatewayv2_api.lambda.idintegration_uri = aws_lambda_function.hello_world.invoke_arnintegration_type = "AWS_PROXY"integration_method = "POST"}resource "aws_apigatewayv2_route" "hello_world" {api_id = aws_apigatewayv2_api.lambda.idroute_key = "GET /hello"target = "integrations/${aws_apigatewayv2_integration.hello_world.id}"}resource "aws_cloudwatch_log_group" "api_gw" {name = "/aws/api_gw/${aws_apigatewayv2_api.lambda.name}"retention_in_days = 30}resource "aws_lambda_permission" "api_gw" {statement_id = "AllowExecutionFromAPIGateway"action = "lambda:InvokeFunction"function_name = aws_lambda_function.hello_world.function_nameprincipal = "apigateway.amazonaws.com"source_arn = "${aws_apigatewayv2_api.lambda.execution_arn}/*/*"}
While the above example might be seen as verbose for a trivial application, the schema this is based on is virtually a one-to-one representation of the AWS APIs for managing these resources, so the level of control that a developer receives is the same as with direct API integration but with the added advantages of state management, drift detection, versioning, testing and collaboration.
Terraform also has a Cloud Development Kit (CDK) available enabling users to define the above using a programming language.
Deploying to AWS with Pulumi
Pulumi is another IaC framework, and it uses programming languages over declarative syntax by default, allowing developers to create more expressive infrastructure deployment recipes. Pulumi's main 'classic' providers are actually backed by Terraform under the hood, so they generally expose the same or similar APIs, with other baked-in assumptions for convenience.
Here’s what it looks like to deploy our “Hello World” example with Pulumi:
import * as aws from '@pulumi/aws'import * as apigateway from '@pulumi/aws-apigateway'// Create a Lambda Functionconst helloHandler = new aws.lambda.CallbackFunction('hello-handler', {callback: async (ev, ctx) => {return {statusCode: 200,body: 'Hello, API Gateway!',}},})// Define an endpoint that invokes a lambda to handle requestsconst api = new apigateway.RestAPI('api', {routes: [{path: '/',method: 'GET',eventHandler: helloHandler,},],})export const url = api.url
The above example is less verbose than the equivalent Terraform example, as this example uses a Pulumi Crosswalk resource library to provide assumptions about the deployment of the API Gateway. This demonstrates the flexibility afforded when using familiar programming languages to define infrastructure. Without the use of crosswalks, this example would be similar in length to the Terraform example.
This example also uses a Pulumi callback lambda function which allows the inclusion of the function code in line with the deployment for greater convenience, but it may not be suitable for larger more complex applications and is not available in all languages that Pulumi supports.
For developers who prefer a more declarative syntax like Terraform’s HCL, Pulumi now also supports YAML (i.e. cuelang).
Deploying to AWS with Nitric
Nitric builds on top of Pulumi by baking the Pulumi automation API into the Nitric CLI, to automate the provisioning of infrastructure recipes based on application intent rather than directly requesting specific cloud resources. This abstraction allows Nitric to provision the same application to many different clouds without having to make changes to the code base.
import { api } from '@nitric/sdk'const helloApi = api('main')helloApi.get('/hello', async (ctx) => {ctx.res.body = `Hello world!`return ctx})
With less than 10 lines of code, this is very convenient. Because Nitric is an abstraction that provides Infrastructure from Code, it does not expose all of the properties you would expect to see in either Pulumi or Terraform.
Nitric instead makes best practice assumptions about non-functional application concerns and automatically applies them, greatly reducing the scope of developer concerns at the cost of more fine-grained control. This can afford large productivity and quality gains by allowing developers to focus solely on their application logic and allows more time for activities such as automated testing.
Automating this process also reduces human error in complex configuration, leading to more robust security and application performance.
Nitric also leaves open the option for more control as needed by allowing escape hatches for specific cloud configuration. This would allow developers to opt into increasing complexity rather than it being the default experience.
Before building the IfC framework, Nitric used YAML for deployment descriptions, much more like an IaC framework. We re-wrote the framework to IfC (which we called config as code at the time) so that we could deliver greater productivity and scalability benefits for cloud development and deployment.
Read more about the technology differences for Terraform vs. Nitric and Pulumi vs. Nitric.
Deploying to Azure with Nitric
One of the benefits of IfC is the portability made possible by the right level of abstraction. In addition to deploying to AWS with the above Nitric example, you could also deploy to Azure or GCP with just a single command. Check out this demo video to see a real application example of what it looks like to use Nitric to build and deploy to Azure.
Comparing IfC to IaC
IfC is not a silver bullet or golden hammer solution to all cloud deployment problems. It is a paradigm shift that accelerates teams that do not need minute control over their infrastructure and are more focused on their applications' logical concerns. This separation between application logic and deployment logic creates several advantages for teams and can allow their applications to be less coupled to specific clouds or infrastructure.
If the characteristics of a specific cloud an application deploys to are a part of the functional concerns of the application, then the control IaC solutions afford would be a better fit than IfC for that application. However, this creates a strong coupling between the solution and its infrastructure and leads to teams essentially maintaining two separate applications: one for their business and another for service deployments for the business application.
IfC does not supersede IaC but builds on top of it and can even complement it. Teams looking to reduce their workload by bringing their applications into the cloud should start looking at IfC offerings now to see where and how these solutions can fit into the stacks they’re maintaining today.
If you'd like to learn more about IfC, trying out Nitric is a great place to start. Check out our docs to get started.
Checkout the latest posts

Build Azure Infrastructure Using AI and Terraform
Learn how to leverage AI and Terraform to build and deploy Azure infrastructure directly from your application code with Nitric.


GenAI Made Terraform More Relevant Than Ever
Infrastructure as Code is more alive than ever, but it is no longer something teams should write line by line.


The Deployment Bottleneck No One Talks About
The real bottleneck might not be in your pipeline but rather in how your application interacts with cloud services.
Get the most out of Nitric
Ship your first app faster with Next-gen infrastructure automation