

Cloud SDKs like AWS, Google Cloud or Microsoft Azure SDKs are often deeply embedded in application code. While this simplifies direct interaction with cloud resources, it also creates significant friction between development and operations teams.
Cloud SDKs provide runtime functionality for specific resources within your application code. Unfortunately, in an effort to offer more convenience to developers, they also require provisioning details to be supplied within the application code itself. This creates a tight coupling between the application and the infrastructure needed to run it.
These SDKs are designed this way because there are multiple pathways to get an application running in the cloud. Their designers aim to support all paths to the cloud, whether you manually configure your app in the cloud console, handle configuration directly within the application code or use Infrastructure as Code (IaC) tools. However, this flexibility comes at a cost.
The moment a developer imports cloud SDKs into their code, they’re not just writing application logic anymore; they’ve become opinionated about their cloud infrastructure, and they are pulled into activities such as managing cloud services, configurations and infrastructure concerns. This shifts their focus from solving business problems to dealing with cloud-specific challenges.
It also introduces complexity for operations teams, which will require extremely detailed documentation of the implementation or, more likely, are left to dig into the application code and engage in time-consuming meetings to understand what needs provisioning.
Wouldn’t it be better if we could truly separate the concerns of our developers and operations teams?
Developers should be able to focus on application logic, not infrastructure specifics or config. Operations should have full control over the infrastructure with the ability to change at any time without rewriting the application. What if we could do it while continuing to use some of the tools that we have grown to love over the years? In the upcoming sections we will discuss how, with the right level of abstraction over cloud resources, we can ensure separation of responsibilities and concerns.
It begins with decoupling our application from direct references to cloud SDKs in our application code. I’ll be using the Nitric framework to demonstrate the concept.
Step 1. Abstraction From Cloud SDKs
The key to decoupling lies in establishing a layer of abstraction that sits above the cloud SDKs, encompassing some of the most frequently used cloud resources. Cloud vendors have matured to the point where most of their foundational services actually deliver the same or extremely similar functionality and value.
We’re talking about APIs, databases, storage buckets, queues, topics and events, scheduled tasks and real-time messaging. These are the foundational building blocks of most applications and APIs, and I’d be extremely surprised if you couldn’t build more than 90% of your application using them alone. By creating this abstraction layer, we enable developers to describe what they want to achieve without dictating how or even where.
For example, when a developer needs to write to a cloud storage bucket, they can simply import the resource from a library SDK that offers them a variety of runtime functionality. The developer needs only provide their intention through the code itself, not the configuration required to set up a specific storage bucket implementation like S3.
In the following example, the developer defines the intent to write to a bucket in a schedule. Unlike a traditional implementation, there is no code here that is specific to the underlying infrastructure.
import { schedule, bucket } from '@nitric/sdk'const profiles = bucket('profiles').allow('write') // Define intentionschedule('process-often').every('1 days', async (ctx) => {const profile = 'image data'await profiles.file('image.png').write(profile) // Execute on intention})
This doesn’t mean that the developer isn’t expected to understand how scheduling and storage work in the cloud. It would be nearly impossible to interact with them without at least a basic understanding, however, they shouldn’t have to worry about where or how they are specifically configured to write their application logic. As per the above example, at the time of writing application code, if you know that you can safely store a file in a storage bucket, then you can delay or defer any decisions about the underlying technology.
This approach separates the developer from the underlying implementation and also gives flexibility to the operations team. Since the developer hasn’t directly imported EventBridge from AWS to handle scheduling, they regain the control to make their own informed choices on what cloud resources should be used to offer this functionality. They also have the ability to change it at their discretion to meet cost, operational and governance requirements without any changes to the application code.
Step 2. Automating Infrastructure Specifications
Now that we have effectively decoupled ourselves from specific cloud implementations, we need to establish a way of communicating our requirements to the team that will provision their concrete infrastructure.
In a traditional solution, this step would be completely manual. Developers and operations teams would have to manually gather requirements so the operations team can understand what the application actually needs to run. In many cases, the ball is thrown over the fence with very little communication. The good news is that because our application code is now standardized by our SDK abstraction, we can scan through it to generate a specification of requirements.
The key here is that we are creating a specification of the runtime requirements of the resources the application uses, not the specific configuration that will make it robust in the cloud — this comes later. Instead, we’re going to scan through the application code and gather resources.
Continuing with our daily schedule example, here is a specification generated from the application code, capturing the necessary resources and relationships. (I’m quite verbose, so I’ve stripped it down slightly to allow skim-reading):
{"resources": [{ "id": { "type": "Bucket", "name": "profiles" }, "bucket": {} },{ "id": { "type": "Topic", "name": "notify" }, "topic": {} },{"id": { "type": "Schedule", "name": "process-often" },"schedule": {"target": { "service": "demo_services-hello" },"every": { "rate": "1 days" }}},{"id": { "type": "Policy", "name": "82368ecb05f907d1657ce3db3261c91a" },"policy": {"principals": [{ "id": { "type": "Service", "name": "demo_services-hello" } }],"actions": ["BucketFileList", "BucketFileGet", "BucketFilePut"],"resources": [{ "id": { "type": "Bucket", "name": "profiles" } }]}},{"id": { "type": "Policy", "name": "193465fec13369ea7725bf91684db329" },"policy": {"principals": [{ "id": { "type": "Service", "name": "demo_services-hello" } }],"actions": ["TopicPublish"],"resources": [{ "id": { "type": "Topic", "name": "notify" } }]}},{"id": { "type": "Service", "name": "demo_services-hello" },"service": {"image": { "uri": "demo_services-hello" },"workers": 1,"type": "default"}}]}
The specification documents the following (and more), as we’ve assigned some IDs for uniqueness:
- Bucket: A storage bucket named
profiles. - Topic: A messaging topic named
notify. - Schedule: A daily task that triggers the service.
- Policies:
- The service requires access to list, get and put files in the
profilesbucket. - The service will publish to the
notifytopic.
- The service requires access to list, get and put files in the
- Service: A worker is required to run the service as an image.
This specification is living documentation. It will stay in sync with changes made to the application like feature enhancements, refactoring, bug fixes, etc. Furthermore, it can be used to generate visual documentation for consumption by team members who don’t have the time to dig through the application code or aren’t programmers.
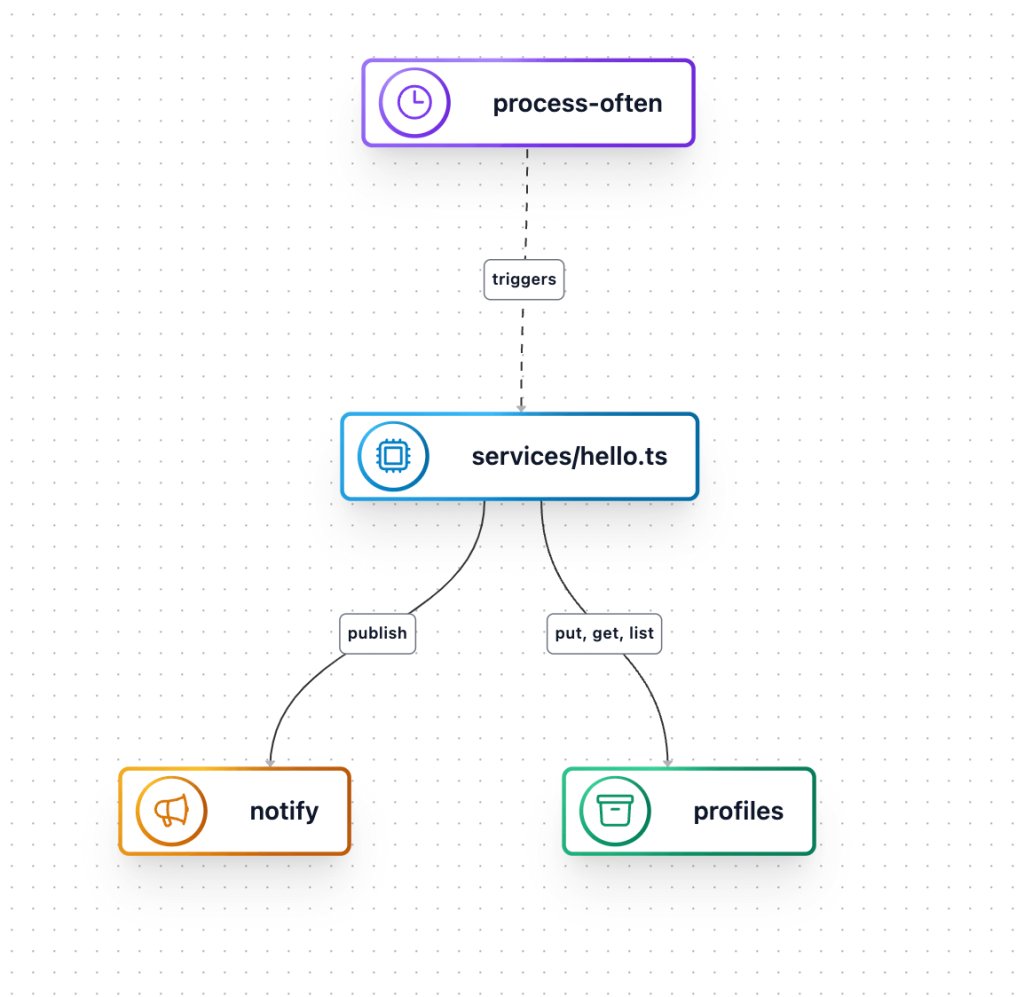
If we stopped at this point, we’d already have significant gains toward addressing communication challenges between developers and operations, but why stop there? We have a requirements document that clearly communicates the runtime needs of our application. We just need to map these requirements to tools that can actually provision our concrete infrastructure and allow us to configure them as per our governance and organizational requirements.
To provide this functionality, we have built a feature that acts like a transpiler for the cloud infrastructure requirements, allowing us to generate a Terraform stack using Cloud Development Kit for Terraform (CDKTF). If you’re interested in the technical details, you can dive in much deeper about it here.
To fulfill an application’s request for a resource, the transpiler will need reusable modules that will provision our APIs, buckets, schedules, etc.
Step 3. Enter Reusable IaC Modules
IaC is the natural first step toward separating the concerns of developers and operations and plays a pivotal role in our automation. By iterating through our specification document, we know the resources we need to provision and configure for our target cloud. Basically, whenever we see a bucket in our specification, we can map it to an IaC module that will provide us with a bucket that is configured with the appropriate permissions, as requested by the application.
Here is an example of provisioning an S3 bucket on AWS using Terraform modules.
The control is actually in the operations team’s hands to decide where the bucket will be provisioned and how it will be configured. For example, you might notice that this is a lightweight implementation without replication policies.
Conclusion
By abstracting cloud SDKs, developers are empowered to focus on writing application logic using their core skill sets without worrying about the underlying infrastructure. Ops, on the other hand, can focus on provisioning and managing cloud resources without having to decipher application code.
The result is a clear separation of responsibilities that reduces friction, improves deployment frequency and allows both teams to work at their highest potential. When we pair this with the ability to auto-generate infrastructure specifications, it ensures that operations have the necessary documentation to create reusable IaC modules, improving consistency and scalability. It’s a win-win for everyone: developers get simplicity and flexibility, while operations gains control and visibility.
We’ve seen communication barriers break down by adopting this approach. So build your next application with Nitric and see it in action for yourself.
Checkout the latest posts

Build Azure Infrastructure Using AI and Terraform
Learn how to leverage AI and Terraform to build and deploy Azure infrastructure directly from your application code with Nitric.


GenAI Made Terraform More Relevant Than Ever
Infrastructure as Code is more alive than ever, but it is no longer something teams should write line by line.

The Deployment Bottleneck No One Talks About
The real bottleneck might not be in your pipeline but rather in how your application interacts with cloud services.
Get the most out of Nitric
Ship your first app faster with Next-gen infrastructure automation